Build Trace #3
shippedReliable Browser Workflow Replay Enterprise RAG
A full enterprise pipeline for the doc search system based on semantic RBAC RAG.
Demo
Watch the workflow replay
Demo summary
A short walk through the pipeline. I ask the same question as a regular employee and then as an executive, and you can see access control change what the system is even allowed to retrieve and answer. Then a look at the live internals on the right: hybrid search, fusion, reranking, caching, and where the time actually goes.
What to watch for
- As an employee, ask about a confidential acquisition. It refuses, because the document was filtered out before search ran.
- Switch to executive and ask again. Now it answers, with citations back to the deal memo.
- The right panel shows every stage and how long each one took. Reranking is the slow part and I do not hide it.
- Ask the same question twice. The second time comes back in about 450ms straight from cache.
- Try a prompt injection. It gets blocked before anything runs.
Problem
The production problem
Most RAG demos stop at: embed some documents, run a vector search, paste the results into a prompt. That works in a notebook and falls apart in a company.
Real enterprise search has constraints the demo ignores. Different people are allowed to see different documents, so the same question has to return different answers depending on who is asking. And you cannot just hide the answer after the fact, you have to control what the system is allowed to look at in the first place. Vector search alone misses exact things like error codes, project names, and acronyms. The most relevant document is often not the most similar one, so you need a second pass that actually reads the query against each candidate. And none of it matters if the model invents things, so answers have to be grounded and cited, or honestly say they do not know.
I wanted to build the real thing, with all of those parts, but small enough to run on a laptop and understand end to end. So I took a published system design case study written for 5000 users and 500k documents and rebuilt it at prototype scale. The rule I set for myself was simple: simplify the scale, never simplify the architecture. Every stage the production design has, this one has too.
What I built
The concrete system
A full enterprise RAG pipeline you can poke at, with a UI that shows its own internals.
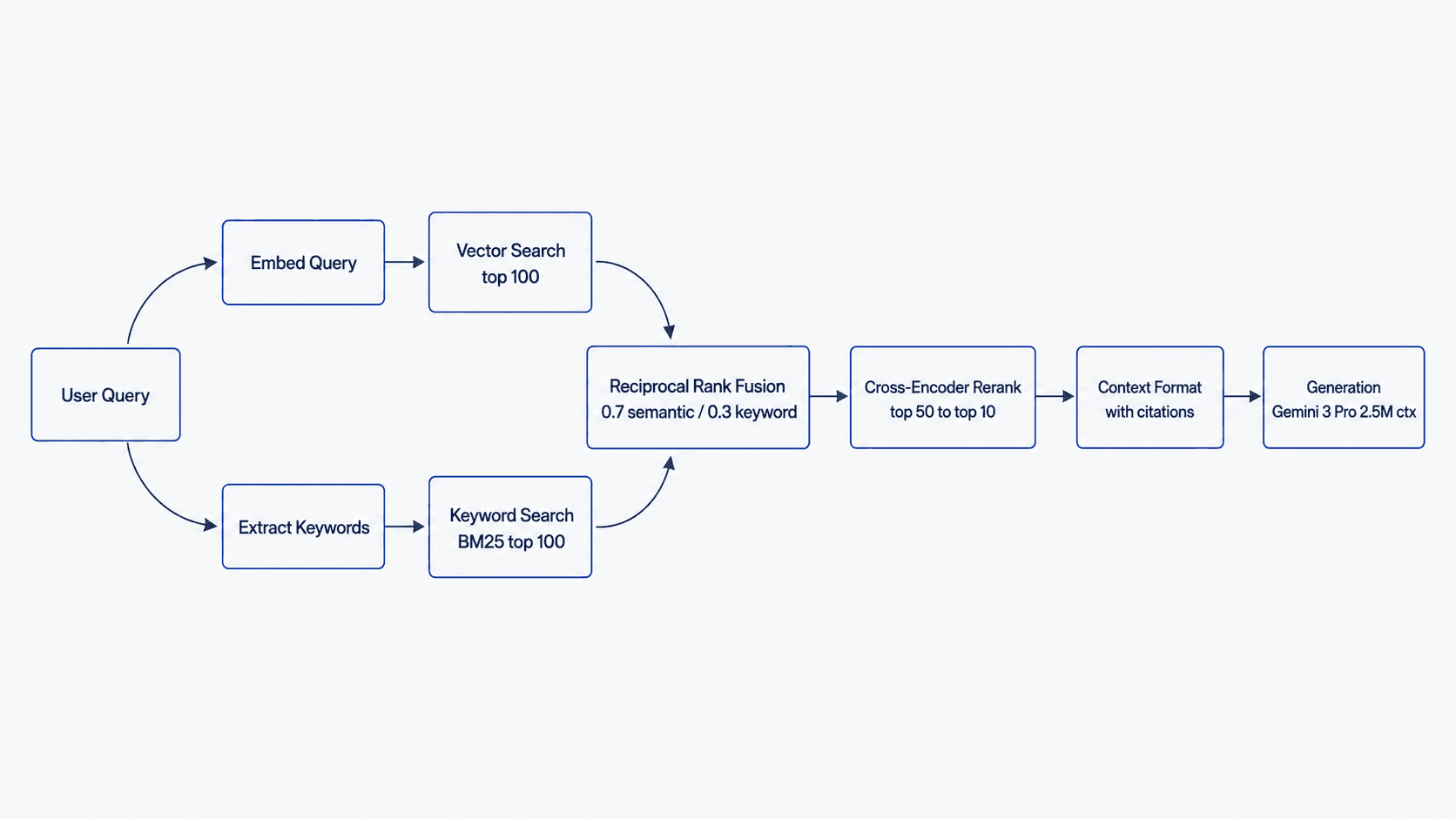
A question goes through input guardrails, an optional history aware rewrite, and a two tier cache. Then hybrid retrieval: a vector search (Qdrant) and a keyword BM25 search (Elasticsearch) run in parallel, both filtered by the user's access level before they run. The two ranked lists are fused with reciprocal rank fusion, a cross encoder reranks the top 50 down to 10, and Claude writes a grounded answer with inline citations while output guardrails check that every citation points at a real source. Every query is logged.
The frontend is a split screen. Chat on the left. A live view of the pipeline on the right: the access levels for the current role, every stage with its latency, the reranking table showing how candidates got reordered, and cache badges. The point of the right side is that you do not have to take my word that the architecture is real. You can watch it work.
Architecture
System shape and data flow
One FastAPI service, one Next.js frontend, and a set of managed services doing the storage. The production case study runs each piece as its own cluster. I run a single node of each on free tiers, which is the whole point of simplify the scale, not the architecture.
The one thing worth calling out is where access control lives. The role maps to a set of access levels, and that set goes straight into the Qdrant filter and the Elasticsearch filter. A document above the user's clearance is never retrieved, never reranked, and never reaches the model. Th

Components
- FastAPI backend, streaming over server sent events
- Next.js frontend with a live pipeline dashboard
- Qdrant for dense vector search
- Elasticsearch for BM25 keyword search
- Supabase Postgres for document metadata and an audit log
- Supabase Storage for the raw documents
- Upstash Redis for the two tier cache
- A local cross encoder reranker (bge-reranker-v2-m3)
Data flow
- Input guardrails: block prompt injection, redact PII
- Rewrite the question into a standalone query if there is chat history
- Check the exact cache first, since it needs no embedding
- Embed the query once with OpenAI and reuse it everywhere
- Check the semantic cache against past queries for this role
- Hybrid retrieval: dense and BM25 in parallel, both filtered by access level
- Reciprocal rank fusion, weighted 0.7 vector and 0.3 keyword
- Cross encoder rerank, 50 candidates down to 10
- Claude writes a grounded, cited answer, streamed token by token
- Output guardrails check the citations, then store the cache and log the query
LLM used for
- Writing the final answer, grounded only in the retrieved documents
- Rewriting follow up questions into standalone queries, only when there is history
- Judging answer faithfulness in the eval harness
Implementation details
Design choices and constraints
A few choices that mattered.
Embed once. The query embedding is computed a single time and reused by both the semantic cache lookup and the dense search. The exact cache is checked before embedding, so identical repeats cost nothing.
Caching is two tiers in Redis, both namespaced by role so a cached answer can never cross a permission boundary. Exact is a hash of role plus query. Semantic stores the query embedding next to the answer and does a cosine scan in process. I set the similarity threshold to 0.90, not the 0.95 from the case study, because with this embedding model real paraphrases landed around 0.71 and 0.95 never fired. An in process scan over a small set is fine at this scale. At real scale you would use a vector native cache.
Reranking is the honest slow part. The cross encoder reads the query against each of the 50 candidates, which is expensive, but it is also the reason the final 10 are actually relevant and not just similar. I show that cost in the UI rather than hide it.
The bug that ate a day: the UI showed nothing while the network tab clearly showed events arriving. The streaming library emits CRLF line endings, so frames are separated by carriage return newline twice, and my parser split on newline newline, which never matched. It received the entire stream and parsed zero events. The fix was one line. The lesson was to suspect your own parser before the backend when the data is on the wire but the screen is blank.
For the public deploy I run Claude Haiku and rate limit per IP with a global daily cap, so a public URL cannot quietly run up a bill. The reranker needs torch and a large model, so the public build skips it and falls back to fusion order, while the full version with reranking is what I record for the demo.
Access control enforced inside the retrieval query
# The role's clearances go straight into the vector search filter.
# A document above the user's access level is never even retrieved.
def dense_search(query_vector, allowed_levels, top_k):
flt = models.Filter(must=[
models.FieldCondition(
key="access_level",
match=models.MatchAny(any=allowed_levels),
)
])
return get_qdrant().query_points(
collection_name=settings.qdrant_collection,
query=query_vector,
query_filter=flt,
limit=top_k,
with_payload=True,
).pointsWeighted reciprocal rank fusion
_K = 60 # standard RRF constant
def reciprocal_rank_fusion(dense, keyword):
scores, pool = {}, {}
for results, weight in ((dense, 0.7), (keyword, 0.3)):
for rank, c in enumerate(results):
scores[c.chunk_id] = scores.get(c.chunk_id, 0.0) + weight / (_K + rank)
pool[c.chunk_id] = c
fused = sorted(pool.values(), key=lambda c: scores[c.chunk_id], reverse=True)
for c in fused:
c.rrf_score = scores[c.chunk_id]
return fusedRelated links