GRPO: How Group Relative Rewards Replaced the PPO Critic
PPO dominated language model post-training for two years. Then DeepSeek's team published a small modification that cut training memory nearly in half while keeping the alignment signal — and now almost every open-source reasoning model uses GRPO instead. Here is how it actually works.
Why This Matters
When DeepSeek released R1 in early 2025, the interesting part was not the benchmark numbers. It was the training recipe. GRPO (Group Relative Policy Optimization) let them train a 671B MoE model's policy head without a separate critic network. That cost reduction cascaded into research labs everywhere. Understanding GRPO from the gradient equations up tells you why Qwen-2.5-Math, Sky-T1, and a dozen other open-weight reasoning models train the way they do — and where the approach quietly breaks.
The Policy Gradient Problem
Start from first principles. You want to fine-tune a language model π_θ so that it generates outputs o for prompt q that maximize some reward r(q, o). The policy gradient theorem says you should take gradient steps in the direction that increases the probability of high-reward outputs:
∇_θ J(θ) = E_{o ~ π_θ}[ r(q, o) · ∇_θ log π_θ(o | q) ]
The intuition is straightforward: increase the log-probability of outputs proportional to how good they are. But there is a problem. The raw reward r(q, o) has high variance as an estimator. If the reward for every output is around 0.6–0.8, the gradient signal is dominated by the absolute value rather than the relative quality difference. The optimizer pushes on everything uniformly, making slow progress.
The fix, which dates back to Williams' REINFORCE (1992), is to subtract a baseline b from the reward:
∇_θ J(θ) = E_{o ~ π_θ}[ (r(q, o) - b) · ∇_θ log π_θ(o | q) ]
As long as b does not depend on o, this is an unbiased estimator with lower variance. The advantage (r - b) tells you: was this output better or worse than expected? That is the signal you actually want.
How PPO Answers This
PPO (Proximal Policy Optimization) learns b directly. It trains a separate value network V_φ(q, o_t) that estimates the expected future reward given the prompt and the tokens generated so far. This is called the critic. The temporal-difference advantage becomes:
A_t = r_t + γ · V_φ(s_{t+1}) - V_φ(s_t)
The critic must be trained simultaneously with the policy, typically at the same parameter scale for good value estimates on long-horizon tasks. On a 7B model, you are maintaining two copies of ~7B parameters in the forward/backward pass. On a 70B model, this is severe. PPO also requires the rollout policy and the learning policy to stay within a KL trust region, enforced by clipping the importance weight ratio:
L_CLIP = E_t[ min(ρ_t · A_t, clip(ρ_t, 1-ε, 1+ε) · A_t) ]
where ρ_t = π_θ(a_t | s_t) / π_old(a_t | s_t)
The clip prevents large policy updates that destabilize training by leaving the trust region.
PPO works well. It is how InstructGPT was trained. But it has two costs that compound at scale: the critic network's memory footprint, and the complexity of keeping the critic's value estimates calibrated as the policy shifts.
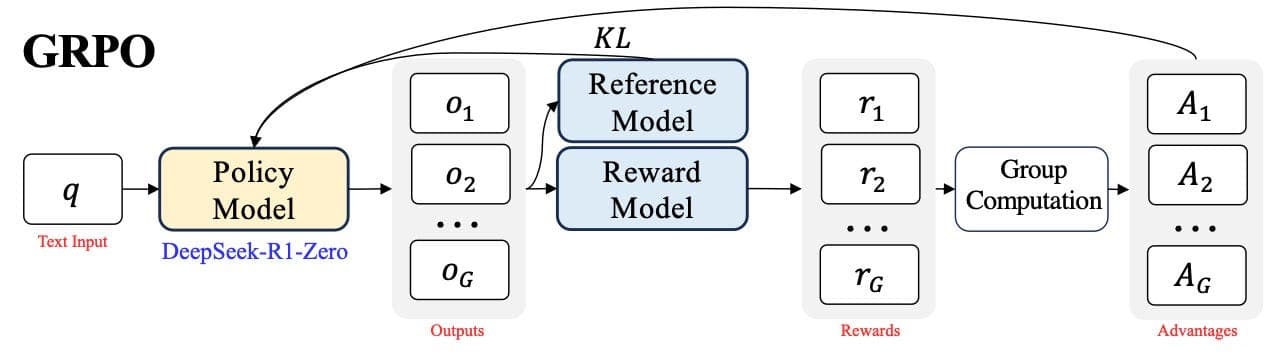
GRPO: Eliminate the Critic with Group Statistics
GRPO, introduced in DeepSeek-Math and refined in DeepSeek-R1, makes one key observation: for tasks with a clear reward function — correct/incorrect math answer, code that passes tests, valid tool call — you do not need a learned value function. You can estimate the baseline from a group of samples.
For each prompt q, sample G outputs from the current policy: {o_1, o_2, ..., o_G}. Score each one with a reward function: {r_1, r_2, ..., r_G}. Then:
μ = (1/G) Σᵢ rᵢ # group mean — this is the baseline
σ = sqrt((1/G) Σᵢ (rᵢ - μ)²) # group std
Aᵢ = (rᵢ - μ) / (σ + ε) # normalized advantage
The group mean is an empirical estimate of the expected reward under the current policy for this specific prompt. No critic needed. The standard deviation normalization makes advantages scale-invariant across prompts. An easy arithmetic problem might have μ=0.9 while a hard integral has μ=0.2; you want gradient magnitudes to be comparable across both.
The full GRPO objective fuses this with PPO-style clipping and a KL penalty against a reference (SFT) policy π_ref:
L_GRPO = (1/G) Σᵢ [ min(ρᵢ · Aᵢ, clip(ρᵢ, 1-ε, 1+ε) · Aᵢ) ] - β · KL(π_θ || π_ref)
where ρᵢ = π_θ(oᵢ | q) / π_old(oᵢ | q)
π_old is the policy frozen at the start of the current optimization mini-batch. π_ref is the SFT checkpoint you are fine-tuning from. The KL penalty keeps the policy from drifting too far from the base model's prior — critical for preserving knowledge and preventing reward hacking.
A Working Implementation Sketch
import torch
def grpo_update(model, ref_model, old_model, prompt_batch, reward_fn,
G=8, eps=0.2, beta=0.01):
total_loss = 0.0
for prompt in prompt_batch:
# Rollout: sample G completions from the frozen old policy
with torch.no_grad():
outputs = old_model.generate(
prompt, num_return_sequences=G,
do_sample=True, max_new_tokens=512
)
rewards = torch.tensor([reward_fn(prompt, o) for o in outputs])
# Group-relative baseline
mu = rewards.mean()
sigma = rewards.std(unbiased=False)
# Skip degenerate groups: all same reward produces zero gradient
if sigma < 1e-6:
continue
advantages = (rewards - mu) / (sigma + 1e-8)
group_loss = 0.0
for o, A in zip(outputs, advantages):
log_pi = model.sequence_log_prob(prompt, o)
with torch.no_grad():
log_pi_old = old_model.sequence_log_prob(prompt, o)
log_pi_ref = ref_model.sequence_log_prob(prompt, o)
# Importance ratio: current policy vs rollout policy
rho = torch.exp(log_pi - log_pi_old)
surrogate = torch.min(
rho * A,
torch.clamp(rho, 1 - eps, 1 + eps) * A
)
# Per-token KL toward reference: E[log π - log π_ref]
kl = (log_pi - log_pi_ref).mean()
group_loss += -surrogate + beta * kl
total_loss += group_loss / G
return total_loss / len(prompt_batch)
sequence_log_prob returns the sum of per-token log probabilities — the log probability of the full completion given the prompt. The KL is approximated as the per-token mean of (log π − log π_ref), which equals the exact per-token KL divergence averaged over sequence length. The σ guard is essential: without it, degenerate groups produce NaN gradients that corrupt the entire batch.
The Training Loop Structure
flowchart TD
A[Sample prompt batch] --> B[π_old generates G outputs per prompt]
B --> C[Reward fn scores all outputs]
C --> D[Compute group μ and σ per prompt]
D --> E{σ near zero?}
E -->|Yes, skip prompt| A
E -->|No| F[Normalize: Aᵢ = rᵢ minus μ over σ]
F --> G[Current π computes log probs]
G --> H[Importance ratio ρ = π over π_old]
H --> I[Clipped surrogate plus KL penalty]
I --> J[Gradient step, update π]
J --> K{Resync π_old?}
K -->|Every N steps| B
K -->|Not yet| G
π_old is resynced every N gradient steps by copying π_θ weights into π_old. Between resyncs, the importance ratio ρ corrects for the distribution shift between when outputs were sampled and when the gradient update runs. In the simplest variant N=1 (resync every step), but N=4–8 improves sample efficiency by reusing rollouts.
Failure Modes
Length Inflation
Binary rewards (0/1 for correct/incorrect) correlate with response length. A model that generates more tokens has more chances to produce the correct final answer — especially on math problems where the boxed answer appears at the end of a long derivation. GRPO exploits this signal and learns to pad. Response length grows monotonically across training steps, often without proportional accuracy gains.
GR3 (March 2026) addresses this with multiplicative group-relative length rescaling. Rather than subtracting a length penalty term — which introduces a new hyperparameter and can suppress correct verbose reasoning — GR3 multiplies the advantage by a group-relative length factor. A correct response shorter than the group average gets a boosted advantage; one that is longer gets penalized. This preserves the correctness signal while breaking the length-reward correlation. Without some form of length control, models starting at 300 tokens per response commonly reach 800+ tokens at 1,000 training steps.
Variance Collapse
When all G outputs for a prompt receive the same reward, σ → 0 and advantages become undefined. Two versions appear at different training stages:
All incorrect (early training): The prompt is too hard. No successful samples exist to reinforce. Every advantage is near zero. No learning happens on the hardest prompts — exactly where you need it most.
All correct (late training): The prompt is too easy. The model has already converged on it. Near-zero advantages everywhere, and compute is wasted.
DeepSeek-R1 filtered the training curriculum to include only prompts where the current policy succeeded on at least 1 and at most G-1 of the G samples. This guarantees a non-zero σ and a real gradient signal on every batch. It is effectively online difficulty filtering through group statistics — an elegant feedback loop where the model's own rollout behavior drives the curriculum.
Credit Assignment in Long-Horizon Tasks
GRPO assigns a single outcome reward to the entire output sequence. Every token in a 500-token chain-of-thought gets the same advantage. For short reasoning chains, this works — the gradient flows primarily to tokens closest in sequence to the outcome. For agentic tasks spanning 30+ sequential tool calls, early tokens receive diffuse, nearly zero gradient. A wrong choice at step 3 of a 40-step agent loop generates essentially no learning signal from an outcome reward applied uniformly across the full trajectory.
ShapE-GRPO (March 2026) applies Shapley values from cooperative game theory to decompose the group reward into per-step contributions. Each generation step is treated as a player in a cooperative game, and the marginal contribution is estimated via sampling across coalition orderings. The result is a meaningful gradient signal for early steps in long-horizon tasks — at the cost of additional forward passes to compute the approximated Shapley values.
KL Sensitivity
β controls regularization toward π_ref and is the hardest hyperparameter to set in GRPO. Below β ≈ 0.001, the policy drifts far from the base model, losing instruction-following behavior and producing hallucinations. Above β ≈ 0.1, the KL penalty dominates the reward gradient and training stalls. The optimal β also shifts as training progresses: early on, the policy is close to π_ref and KL penalties are small; later, the policy has diverged substantially and the same β applies much larger penalties than intended.
Adaptive β scheduling — monitoring running average KL and adjusting β to maintain a target band of 0.02–0.05 nats/token — is more robust than a fixed value. Some implementations use a simple PI controller on β. This adds engineering complexity but removes the most painful hyperparameter from the equation.
The Actual Memory Savings
A standard PPO training setup holds in GPU memory simultaneously:
- Policy: forward pass + backward pass → roughly 2× parameter memory
- Critic: forward pass + backward pass → roughly 2× parameter memory
- Reference policy: forward pass only → 1× parameter memory
- Rollout policy: forward pass only → 1× parameter memory
Total: roughly 6× the base model's parameter memory, before optimizer states and activations.
GRPO drops the critic entirely:
- Policy: forward + backward → 2×
- Reference policy: forward only → 1×
- Rollout policy: forward only → 1×
Total: roughly 4× base model parameter memory. For a 70B model with fp16 weights (~140GB), this is the difference between ~840GB and ~560GB of raw parameter memory — a real infrastructure difference when fitting training onto a specific cluster budget.
The offset is G generation forward passes per prompt rather than 1. Generation passes are lighter than backward passes (no stored activations for gradient computation), and they are embarrassingly parallel across the G samples. For most hardware setups, GRPO's additional generation cost is cheaper than maintaining a synchronized critic network across the training cluster.
Practitioner's Lens
GRPO is the right default for verifiable tasks: math with a symbolic checker, code with test execution, tool calls with schema validation, or any task where binary or scalar rewards are cheap to compute without a learned reward model.
Group size G=8 is the practical starting point. G=4 trains fast but produces noisy baselines on medium-difficulty prompts where the difference between 1 and 2 successes determines the advantage. G=16 gives cleaner baselines at 2× generation cost. G=32 is only worth it for prompts where success probability is below 10%.
Instrument response length from step 1. Log mean and 95th-percentile response length per training batch. If length grows faster than accuracy improves, add GR3-style length rescaling before the problem compounds.
For agentic tasks with more than ~10 sequential decisions, outcome-only GRPO signal degrades noticeably. The gradient reaching early tool calls is too diffuse. Invest in a process reward model (PRM) that scores intermediate steps, or consider per-step credit assignment via ShapE-GRPO.
Set β=0.01 as a starting point. Log average KL per token every 100 steps. If it exceeds 0.05 nats, investigate whether the reward function is miscalibrated before adjusting β.
Further Reading
- DeepSeek-Math: Pushing the Limits of Mathematical Reasoning in Open Language Models — original GRPO paper, January 2024
- DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning — the recipe that made GRPO the standard, January 2025
- GR3: Tackling Length Inflation Without Trade-offs — group-relative length rescaling, March 2026
- ShapE-GRPO: Shapley-Enhanced Reward Allocation for Multi-Candidate LLM Training — per-step credit assignment for multi-candidate settings, March 2026
- GTPO and GRPO-S: Token and Sequence-Level Reward Shaping with Policy Entropy — fine-grained credit assignment with dynamic entropy weighting