Writing
Blog
Thoughts on AI systems, multi-agent orchestration, LLM inference, and production engineering.
SWE-bench's Hidden Flaw: Test-Passing ≠ Bug-Fixing
SWE-bench grades coding agents by running the tests the original PR touched — a cheaper proxy than genuine bug-fixing. Three distinct failure modes let agents score well without solving anything: oracle gaming, training-data memorization, and distribution mismatch.
The Consensus Trap: When Majority Voting in Multi-Agent LLMs Fails
Majority voting in multi-agent LLMs fails when adversarial agents form a coordinated minority. Token-level round-robin changes aggregation from a linear vote-sum to a nonlinear operator product. Here's the math and what it means for production agent pipelines.
SMC Speculative Decoding: Beating Rejection Sampling
Standard speculative decoding's rejection sampling wastes computation on every token it rejects. SMC-SD replaces hard rejection with importance-weighted resampling across N parallel draft particles, achieving 2.36× speedup over standard spec decode and 5.2× over autoregressive.
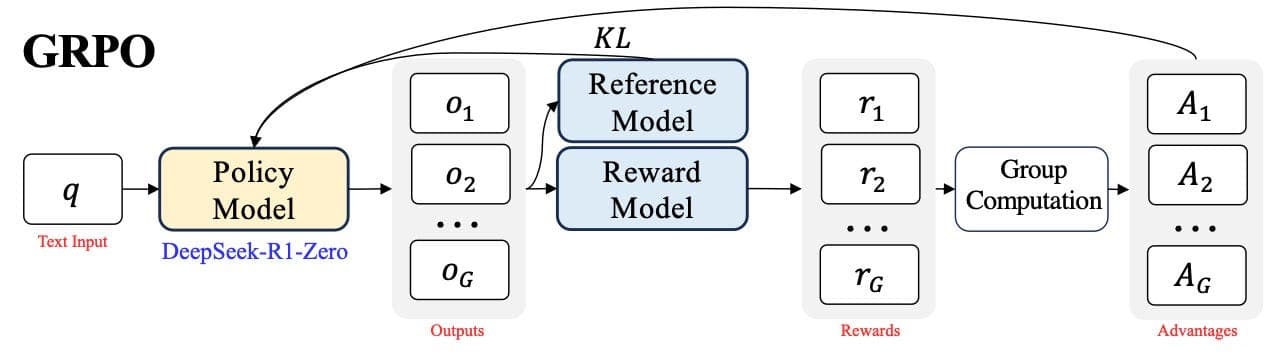
GRPO: How Group Relative Rewards Replaced the PPO Critic
PPO's separate critic network doubles training memory at scale. GRPO eliminates it by computing baselines from a group of sampled outputs. Here's the math, the code, and where it breaks.
Looped Language Models: Thinking Deeper Without Getting Bigger
A 2.6B looped transformer matches a 12B standard model on reasoning benchmarks. The trick: reuse the same block L times in latent space instead of emitting CoT tokens. Here is how Ouro, fixed-point mechanics, and adaptive halting actually work.